Matt Montag - EEN 540 Speech Signal Processing - Project 2
MATLAB Files
speechproduction.m project script
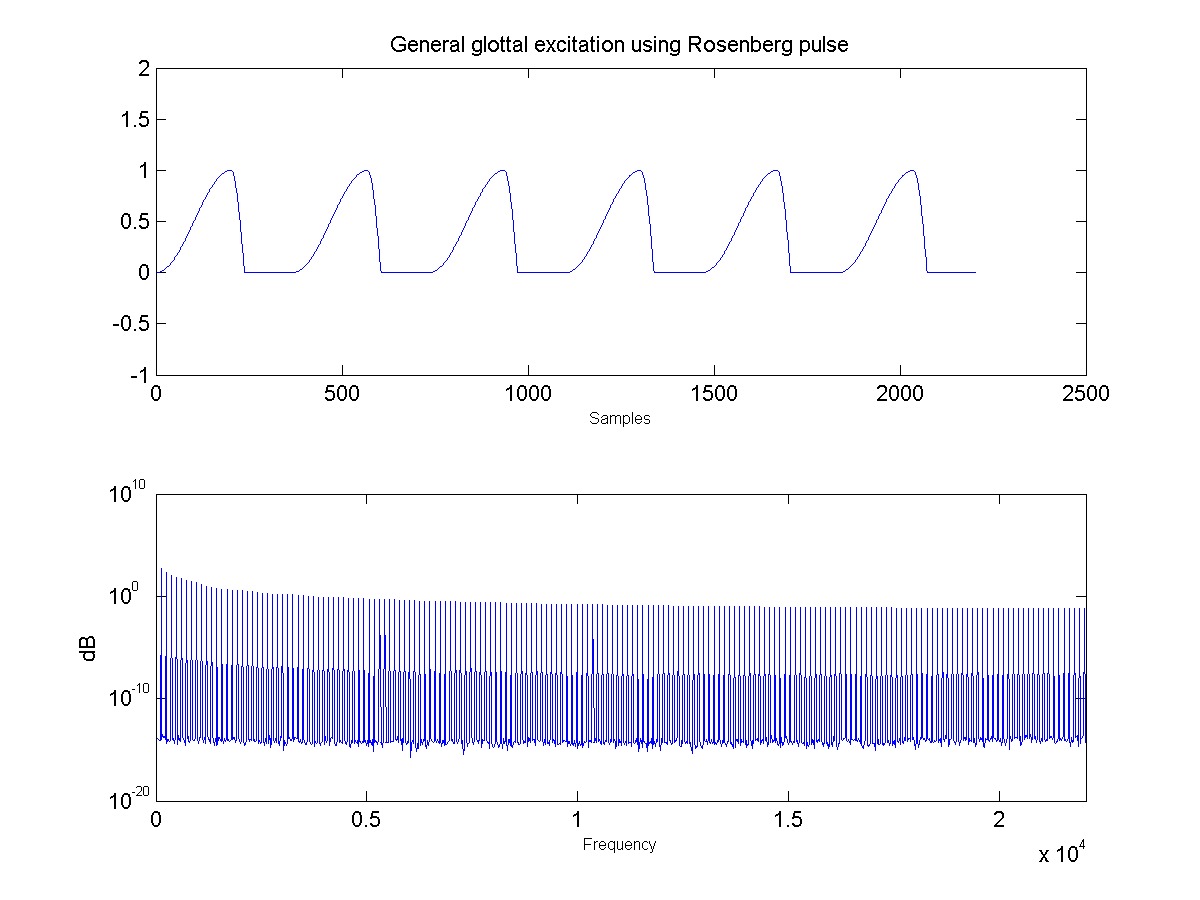
rosenberg.m a script for generating one cycle of a Rosenberg pulse
pad.m utility script for making sure vectors are of matching dimensions
Discussion
In this project, the vocal tract is approximated as a series of connected lossless tubes. Data on the cross-sectional area of the vocal tract for vowels /a/, /e/, /i/, /o/, and /u/ was provided. The tubes were downsampled with linear interpolation to obtain a new series of tubes, depending on the sample rate and simulated vocal tract length.
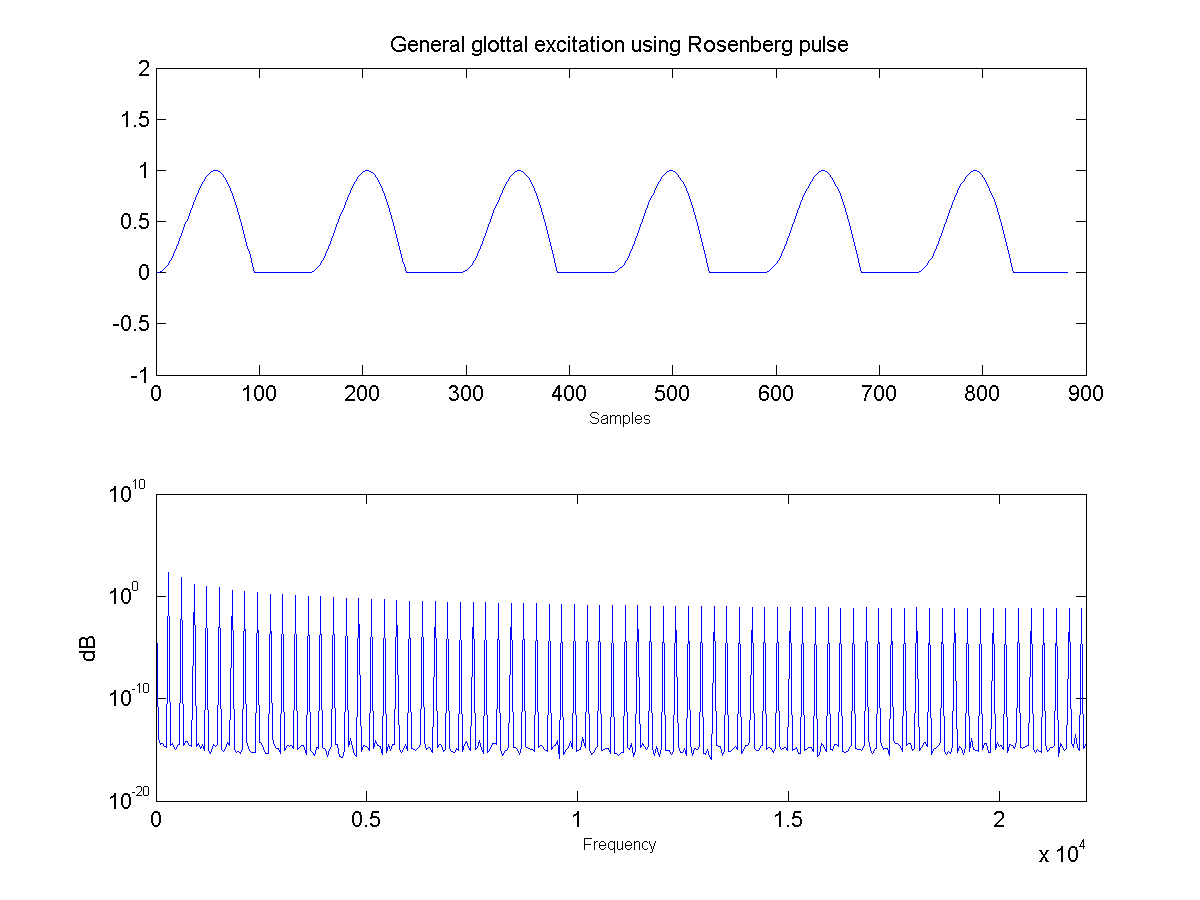
The connected tube model was analyzed to determine the reflection coefficient at each tube boundary. This was then converted to an IIR transfer function representing the transfer from glottal source to output at the lips, which could be applied to a glottal pulse signal to obtain a synthetic human vowel sound. The audio files were generated at a sample rate of 44100 hz.
I made a few tweaks to the system to achieve a more natural vowel sound:
- First, the glottal pulse is perturbed with noise to simulate air turbulence ("breathiness") at the glottis. Importantly, this noise is not applied to the entire glottal signal, but only in the positive region where the glottis is open and air flow is present.
- Second, the pitch and amplitude envelope for the speech was manipulated to add a small random inflection and natural energy decay at the release of vocal stress.
- Third, two or three sharp, quiet "startup pulses" are inserted at the beginning of the glottal pulse train, which represents a subtle glottal fricative at the onset of the vowel. This aids in the realism of the vocal attack.
- Fourth, the signal was low passed with a zero at nyquist to reduce high frequency ringing.

Voiced onset with startup pulse, amplitude envelope, and visible turbulent noise.

Voiced release with rapid pitch and amplitude decay.
Vocal Synthesis Results
Please click on any image below for a full-size version.
Male Speaker |
Female SpeakerGlottal Pulse |
Child SpeakerGlottal Pulse |
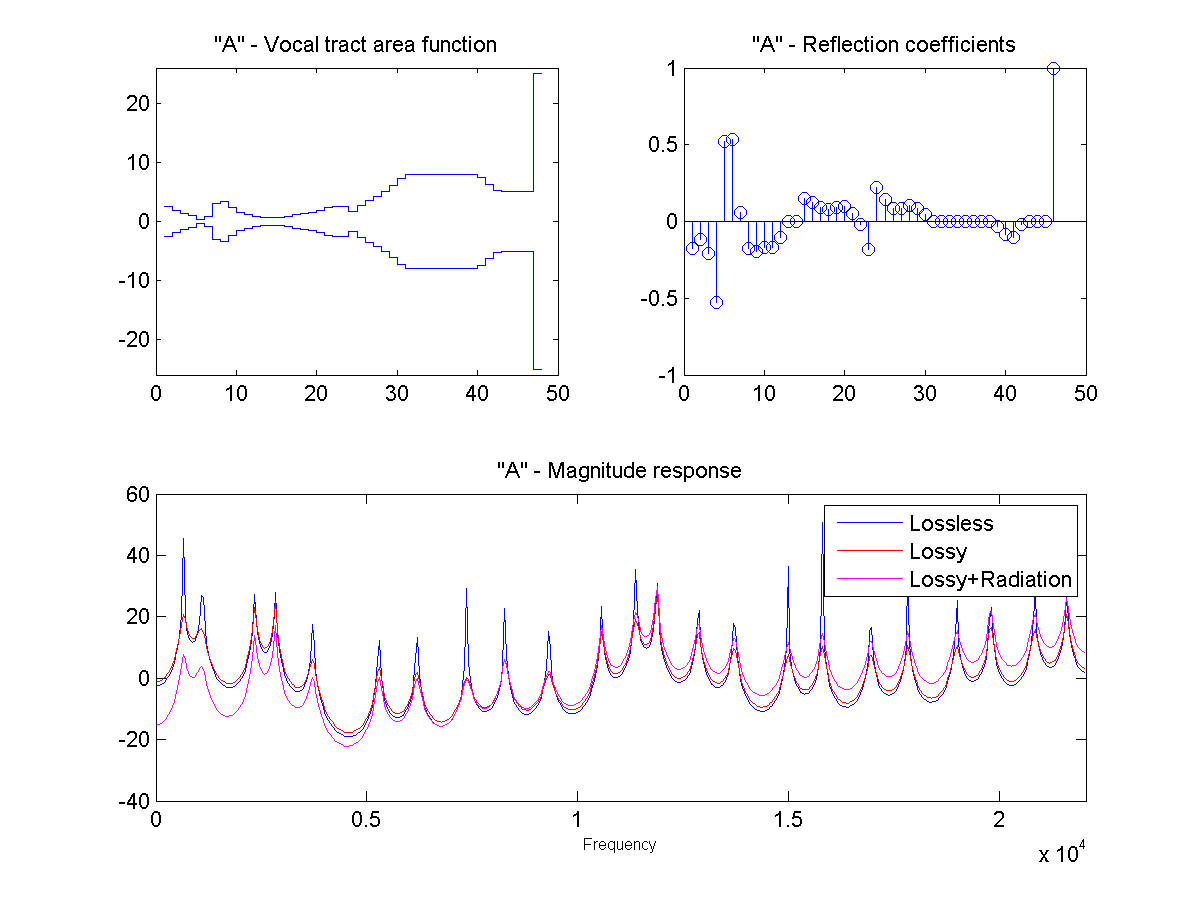
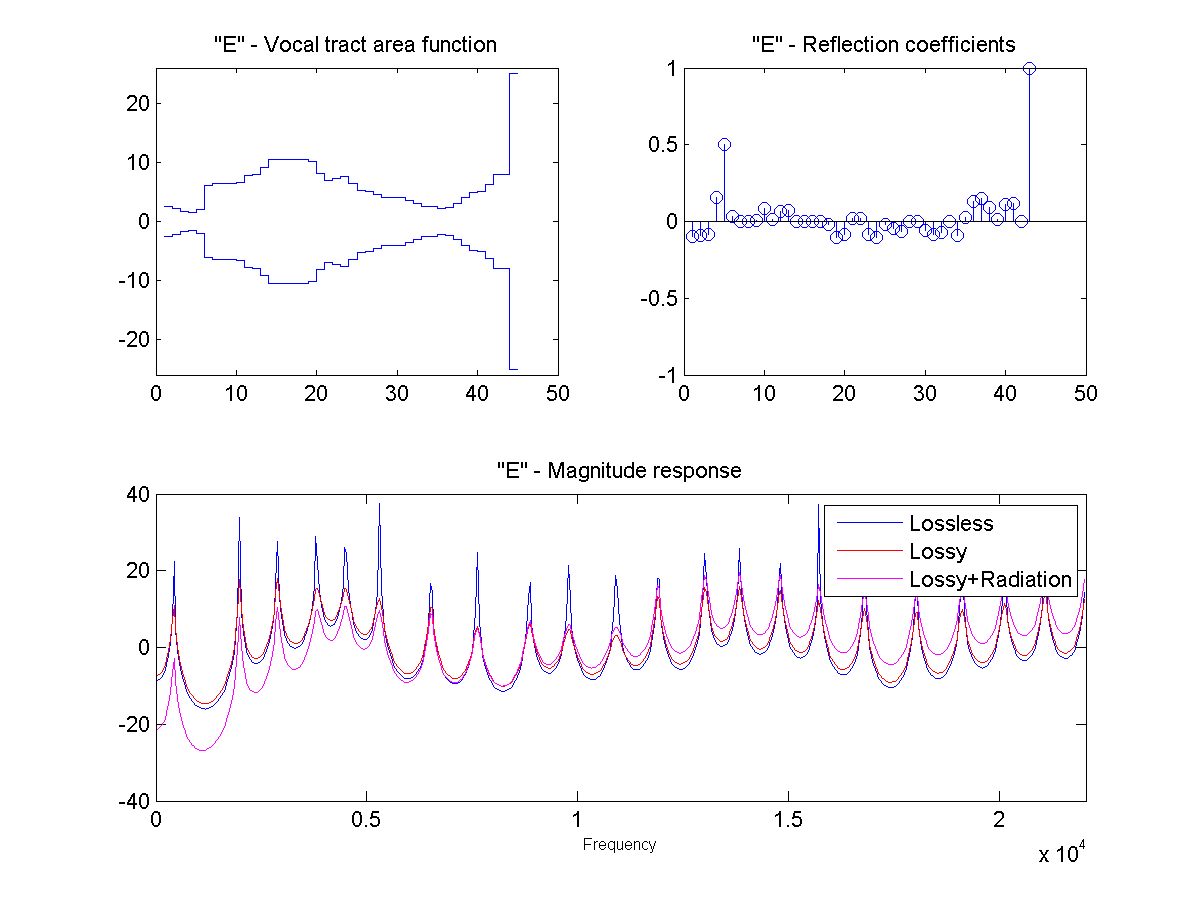
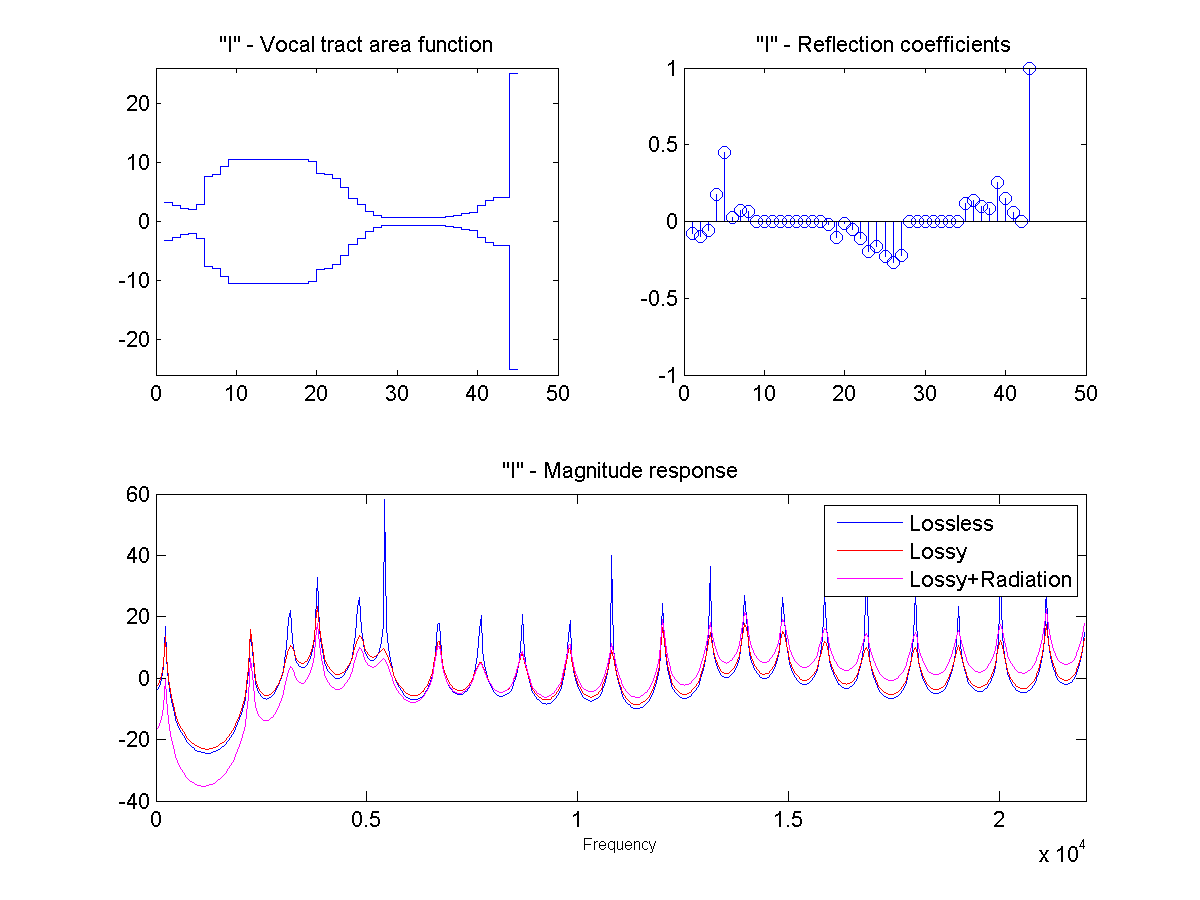
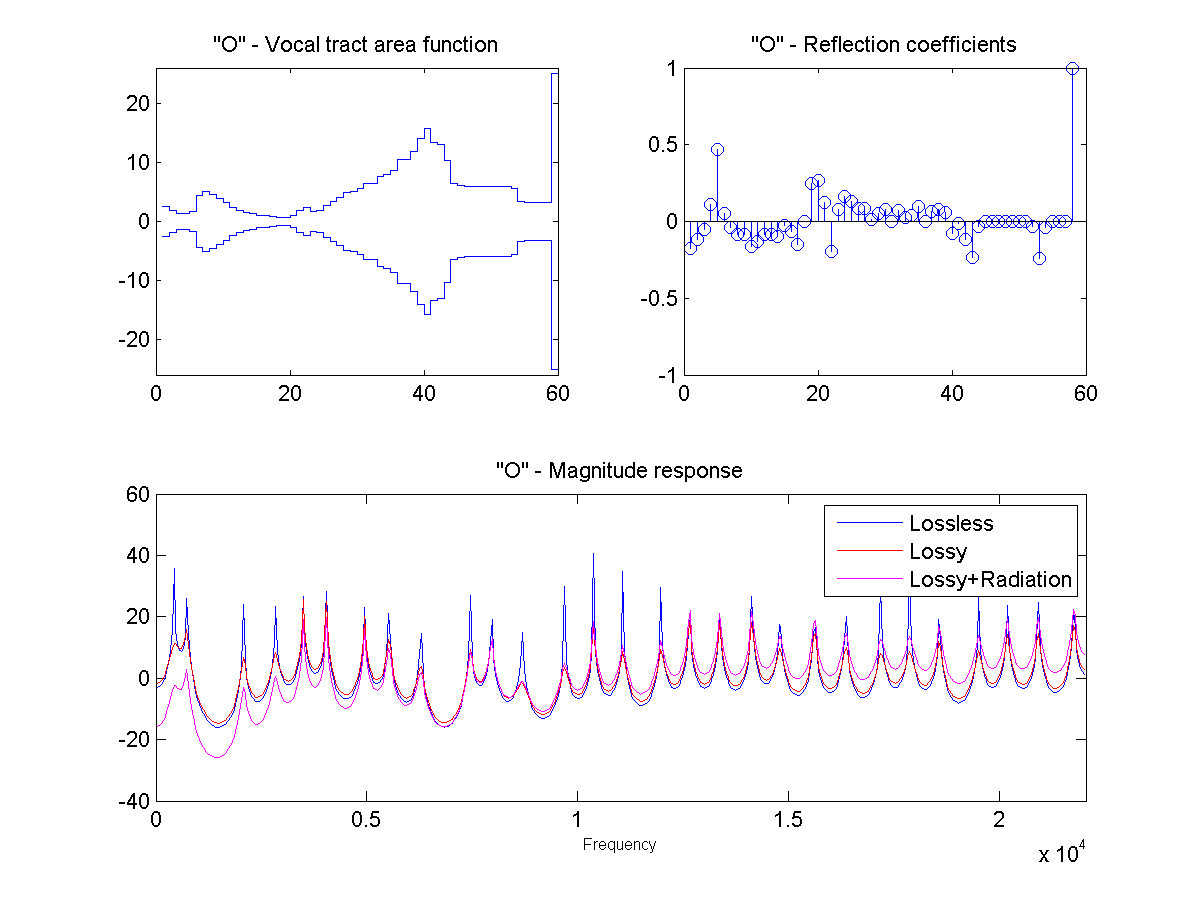
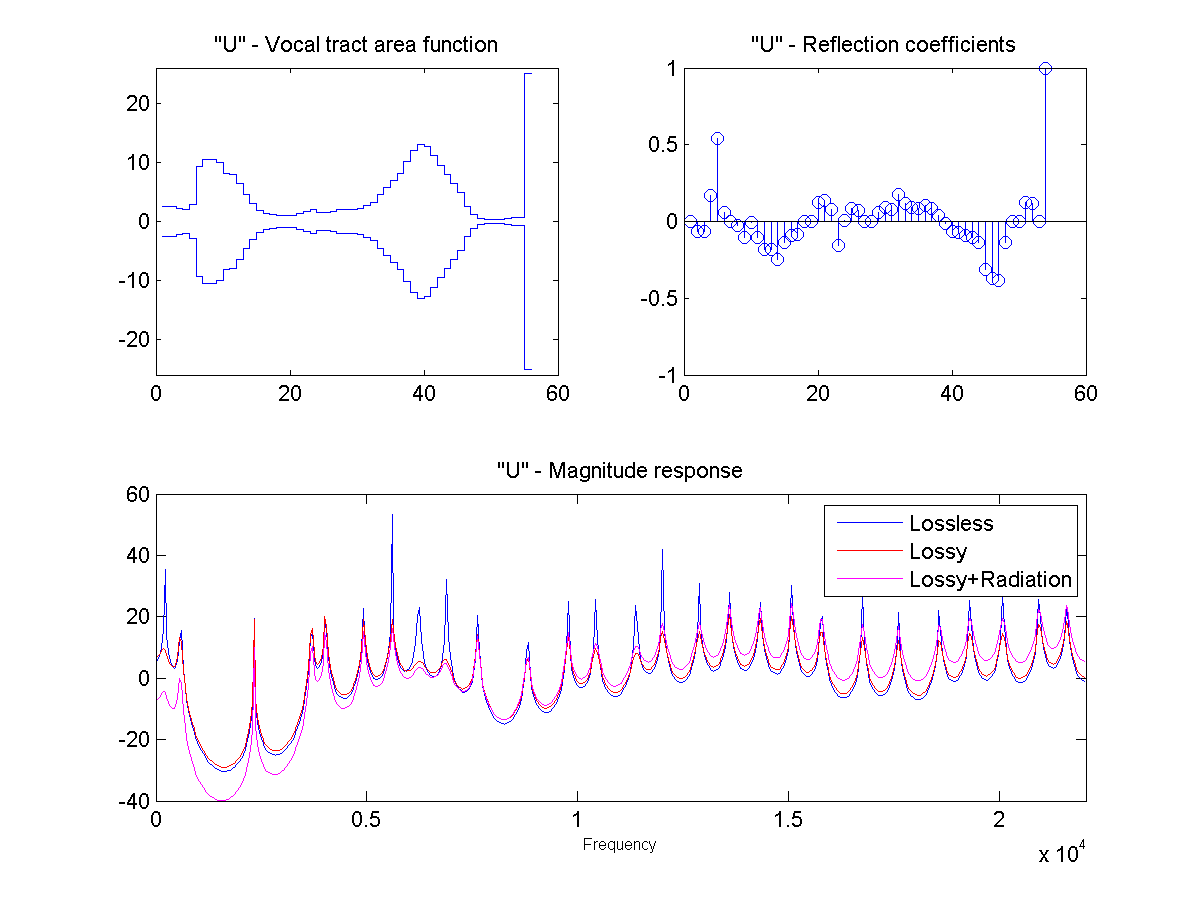
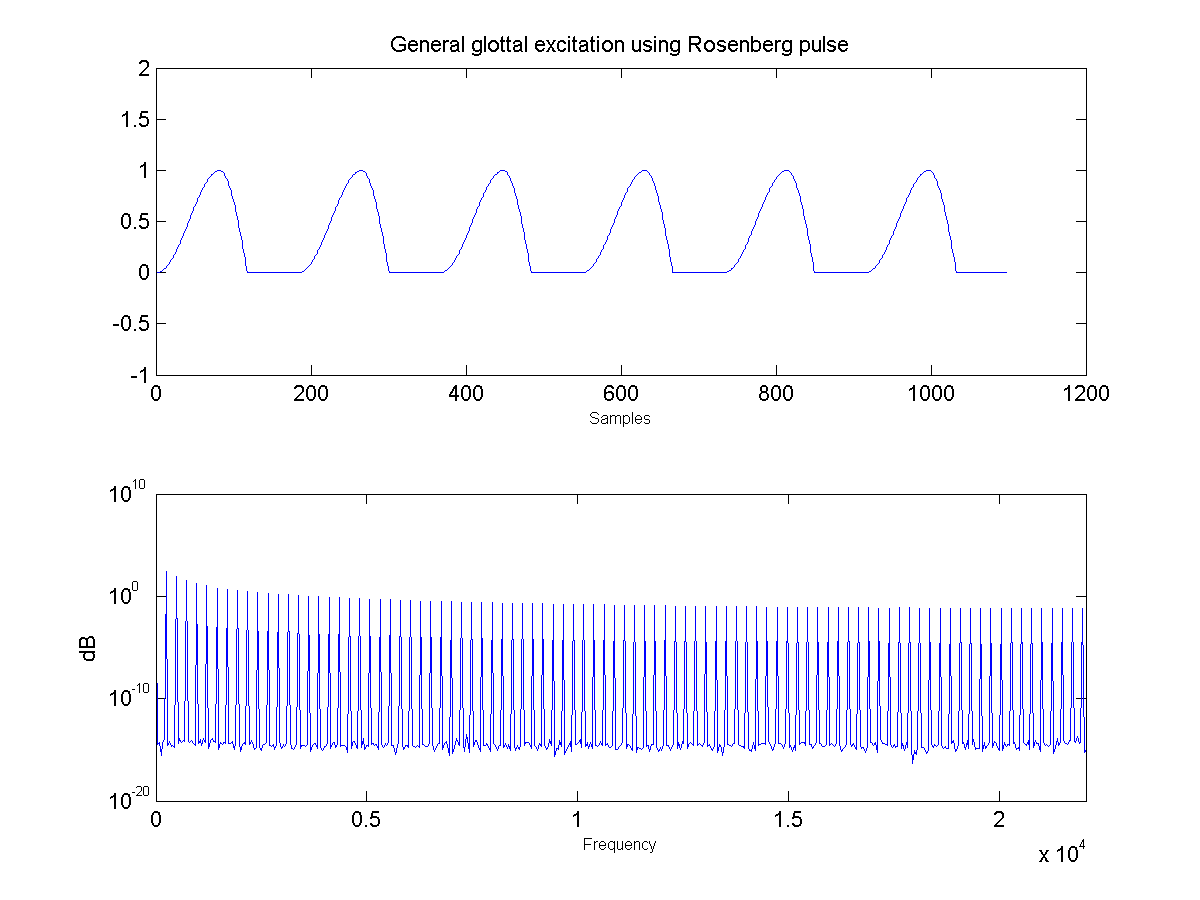
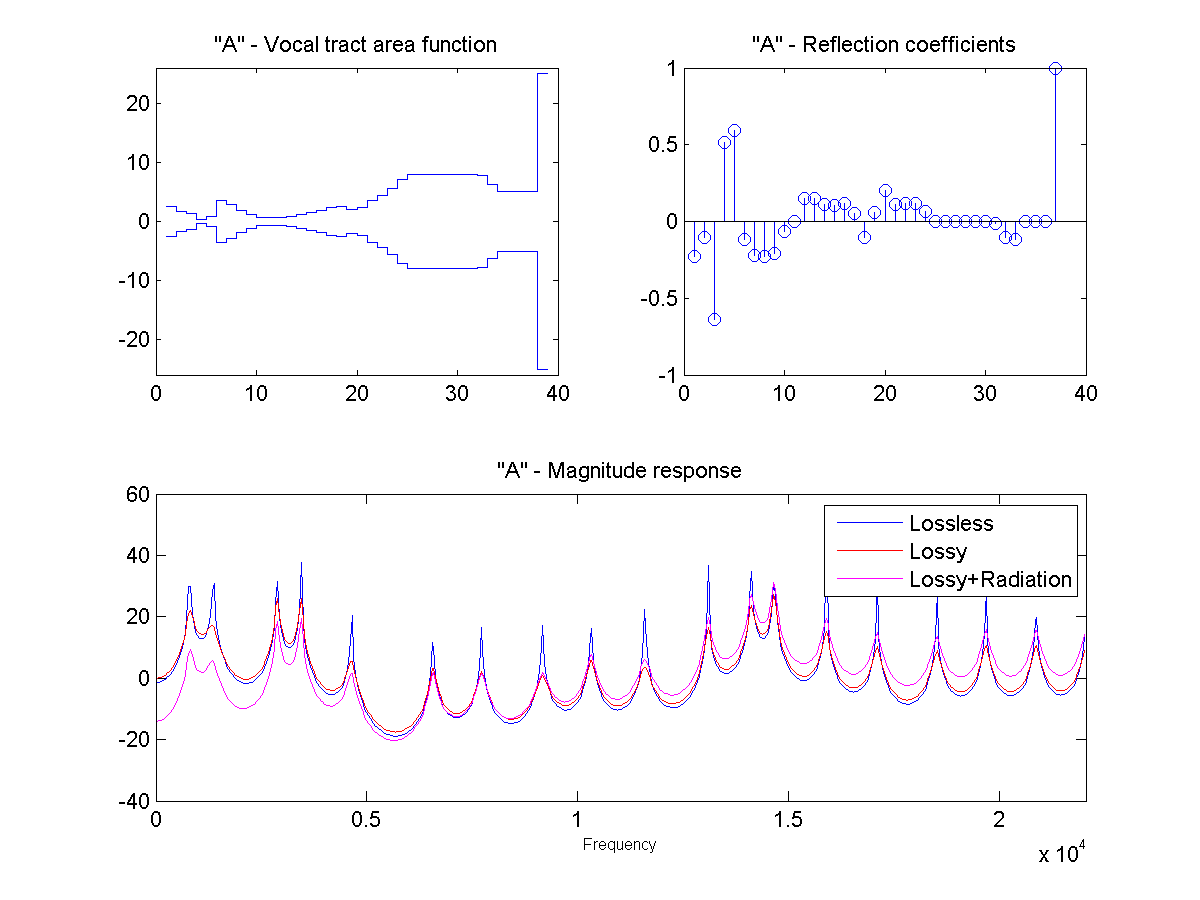
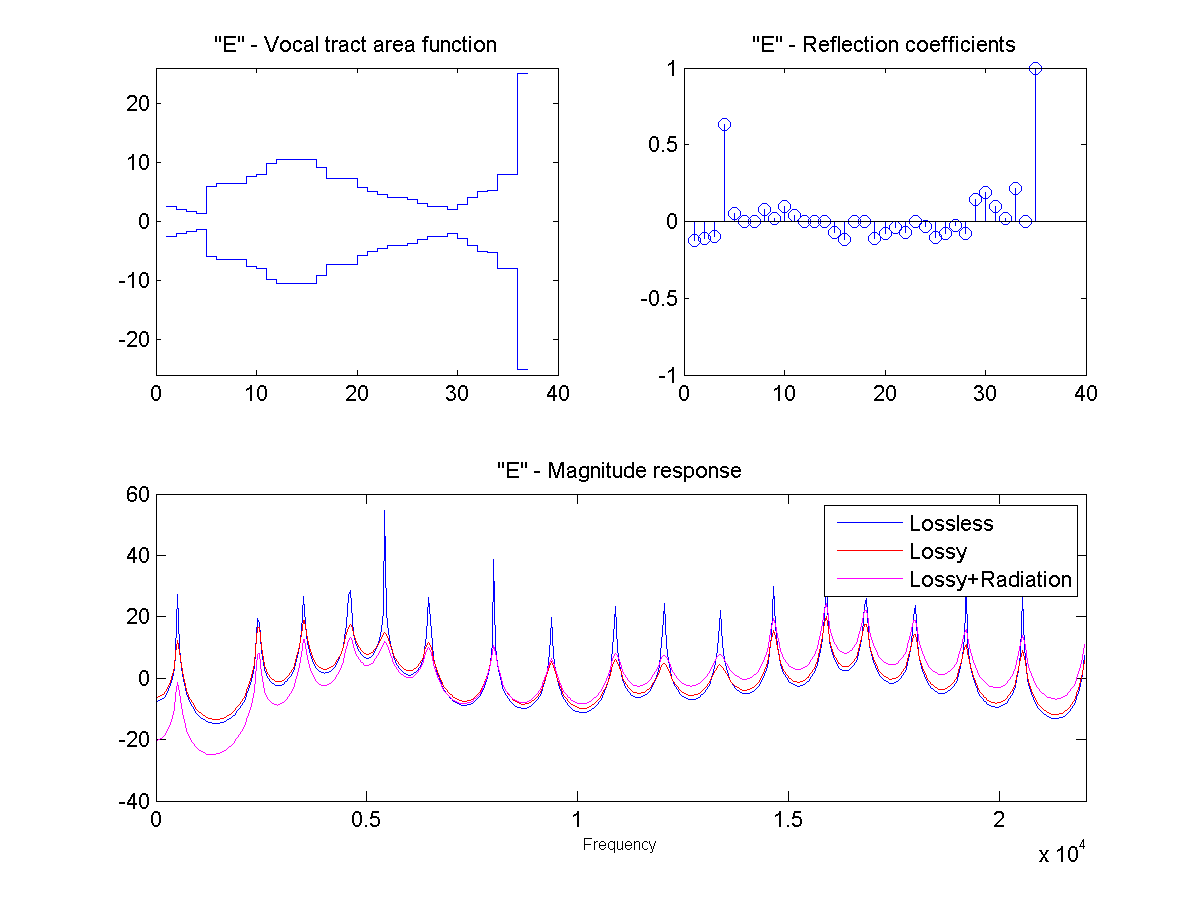
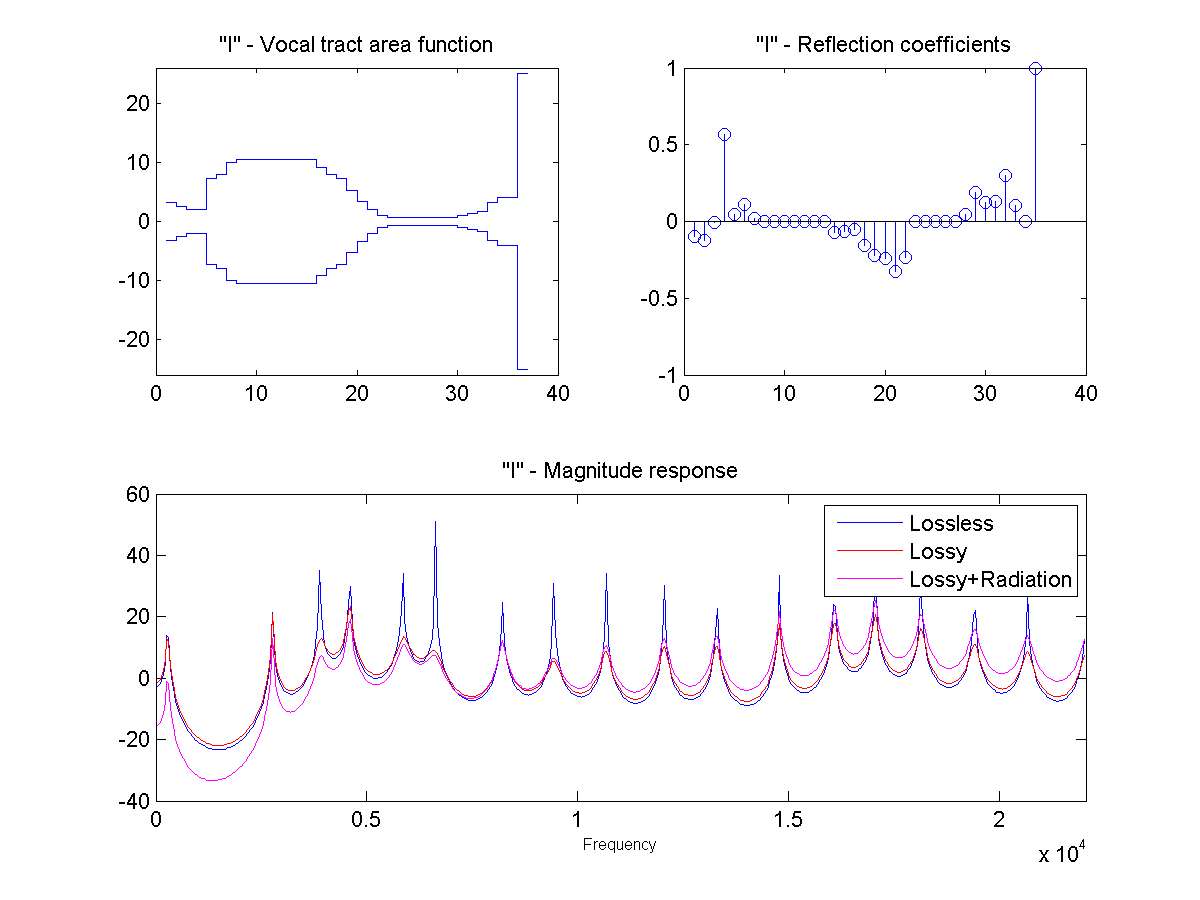
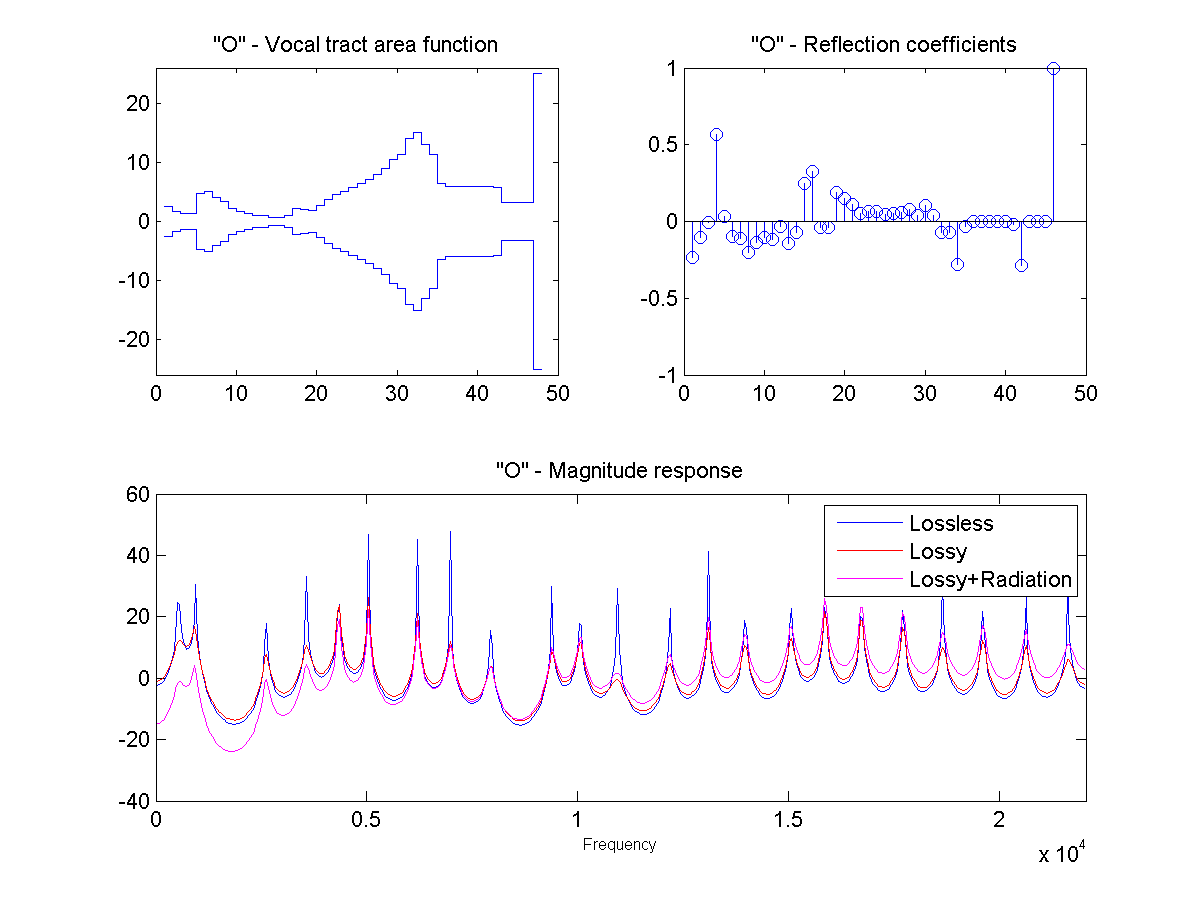
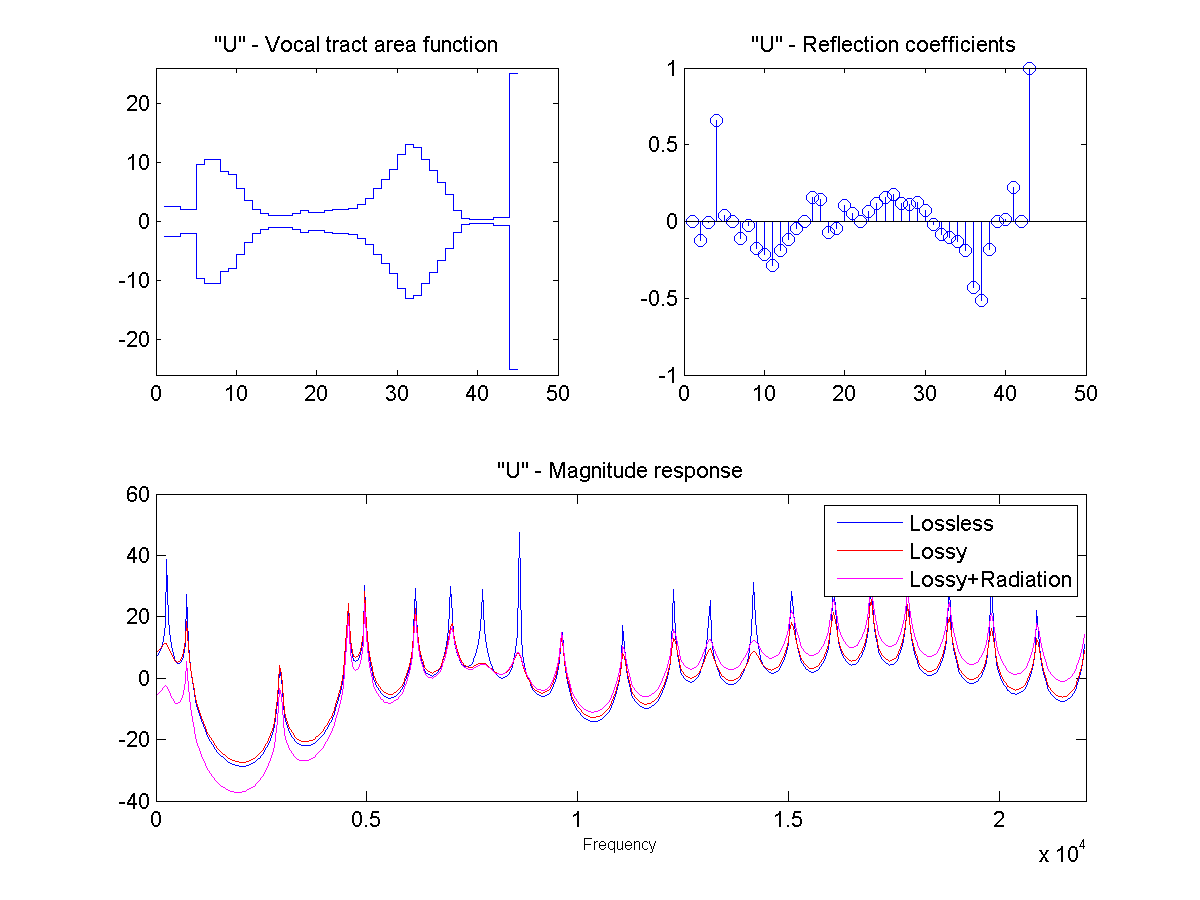
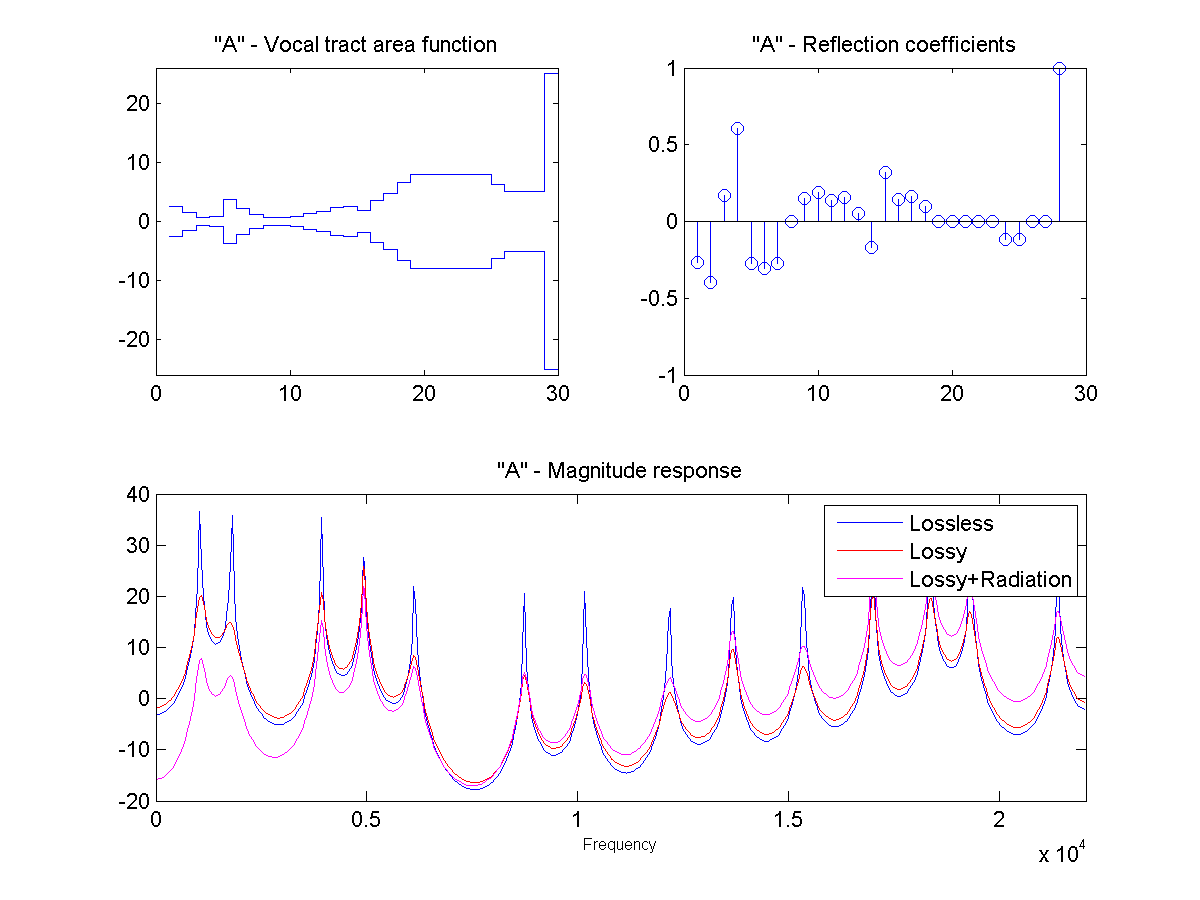
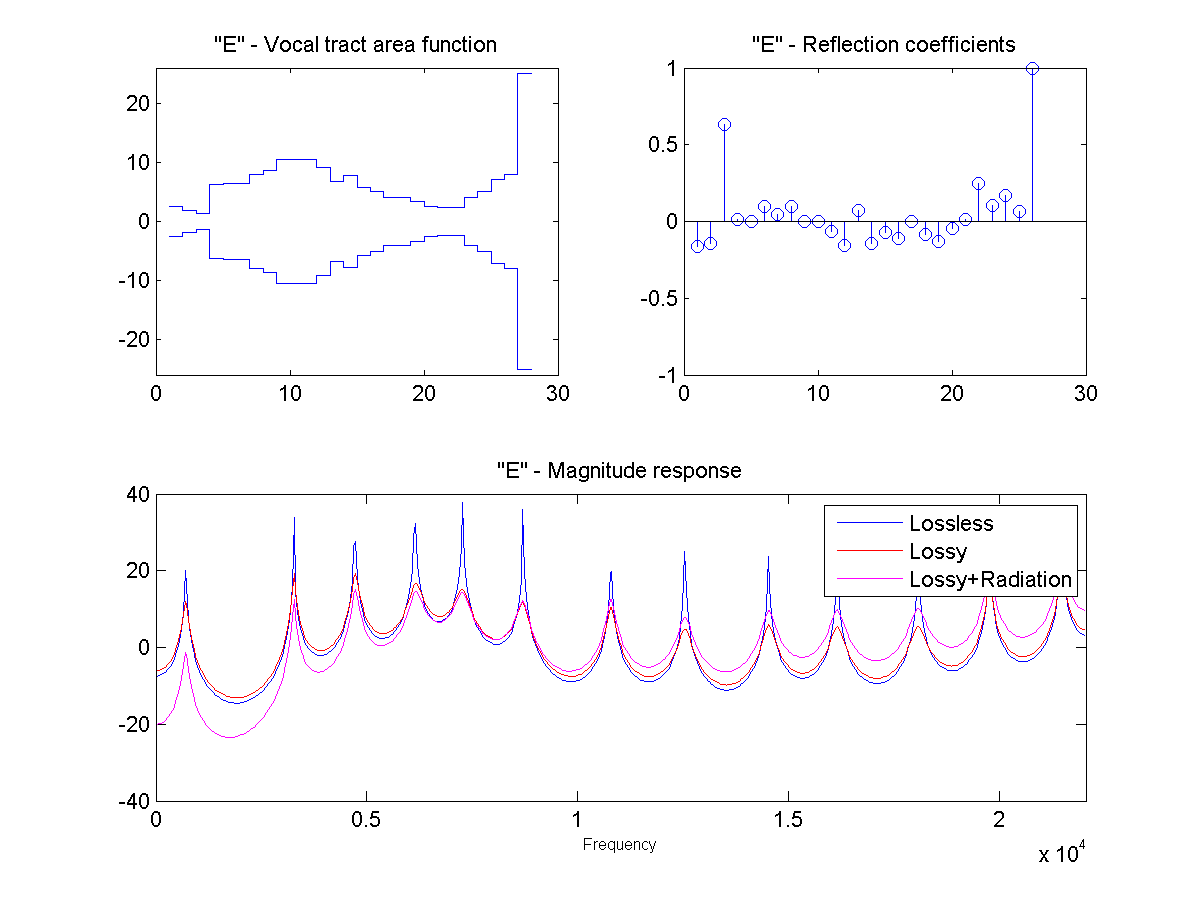
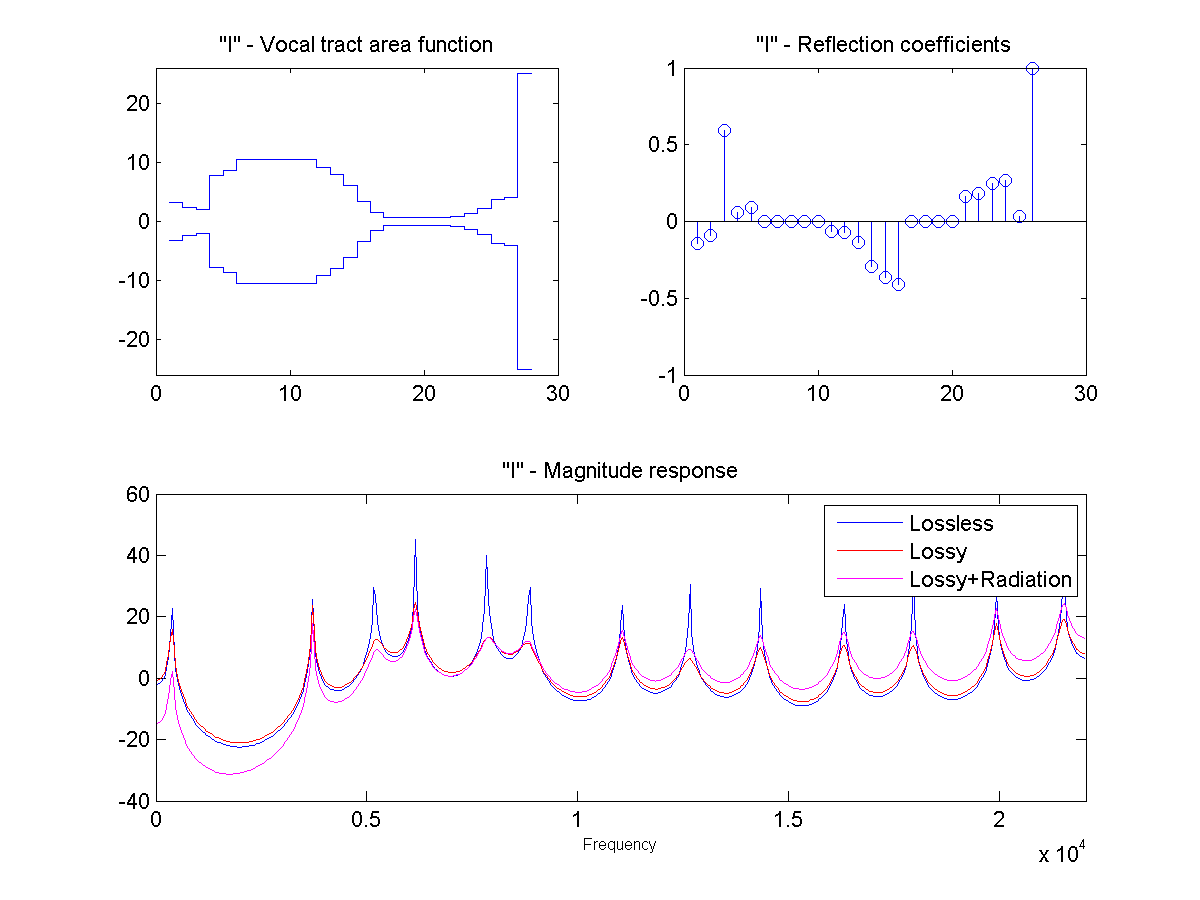
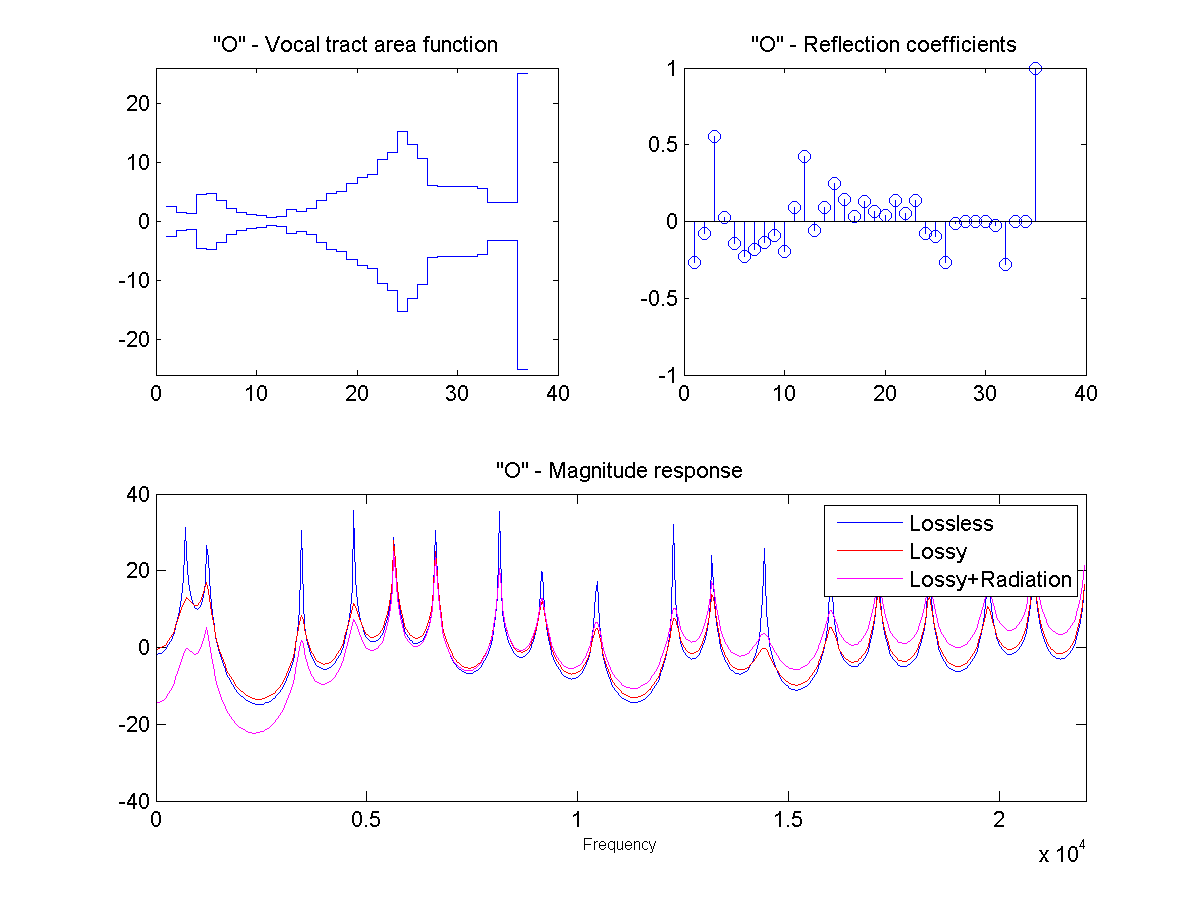
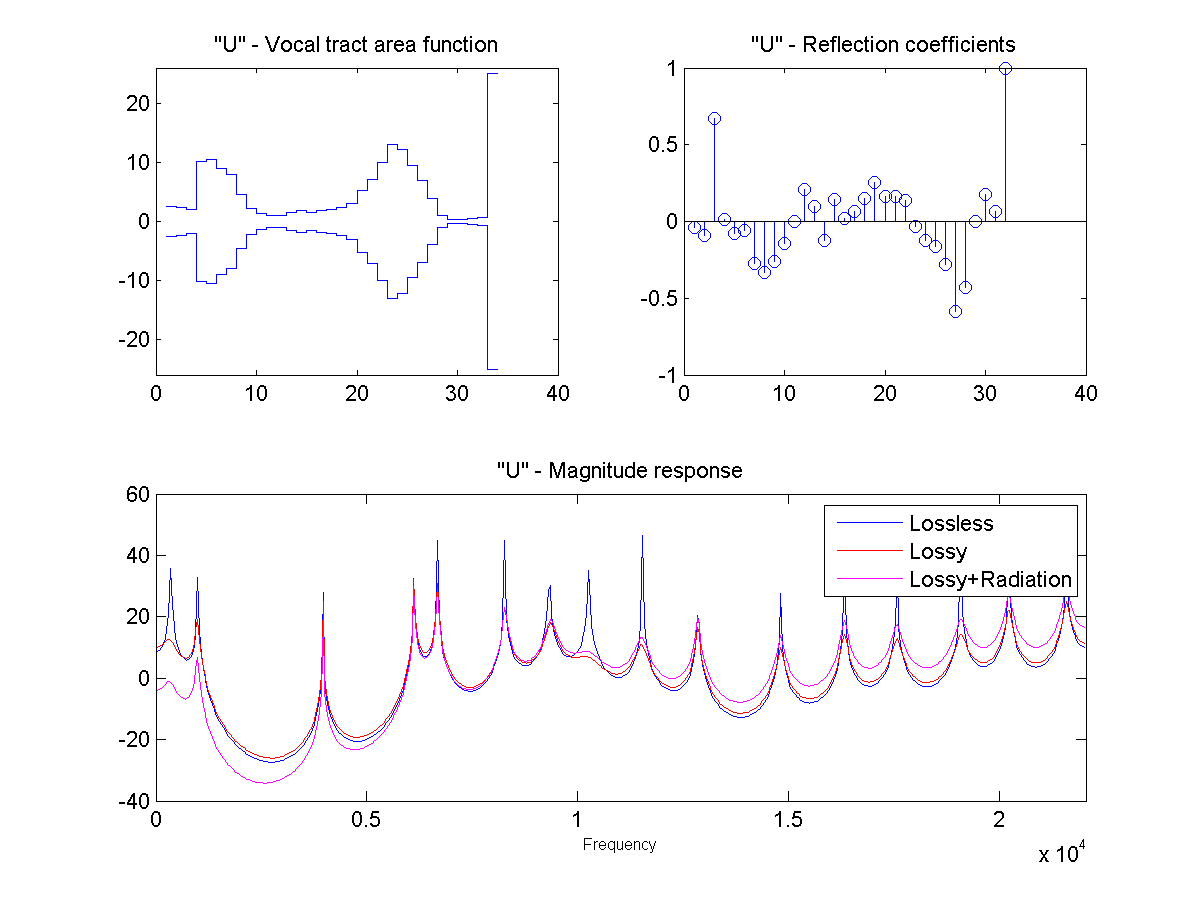
Sound Through a Tunnel
Hear what it would sound like to speak through a "concatenated tube" tunnel with perfect transmission at the tube boundaries - a reverberant, metallic sound. This was constructed with tubes of random sizes concatenated at a regular interval. I noted in this experiment that sharper discontinuities in the tube boundaries led to more pronounced, ringing resonance. I used a running-average to make the tube boundaries smooth and more life-like.
Concatenated Tube Model of a 10 Meter Tunnel
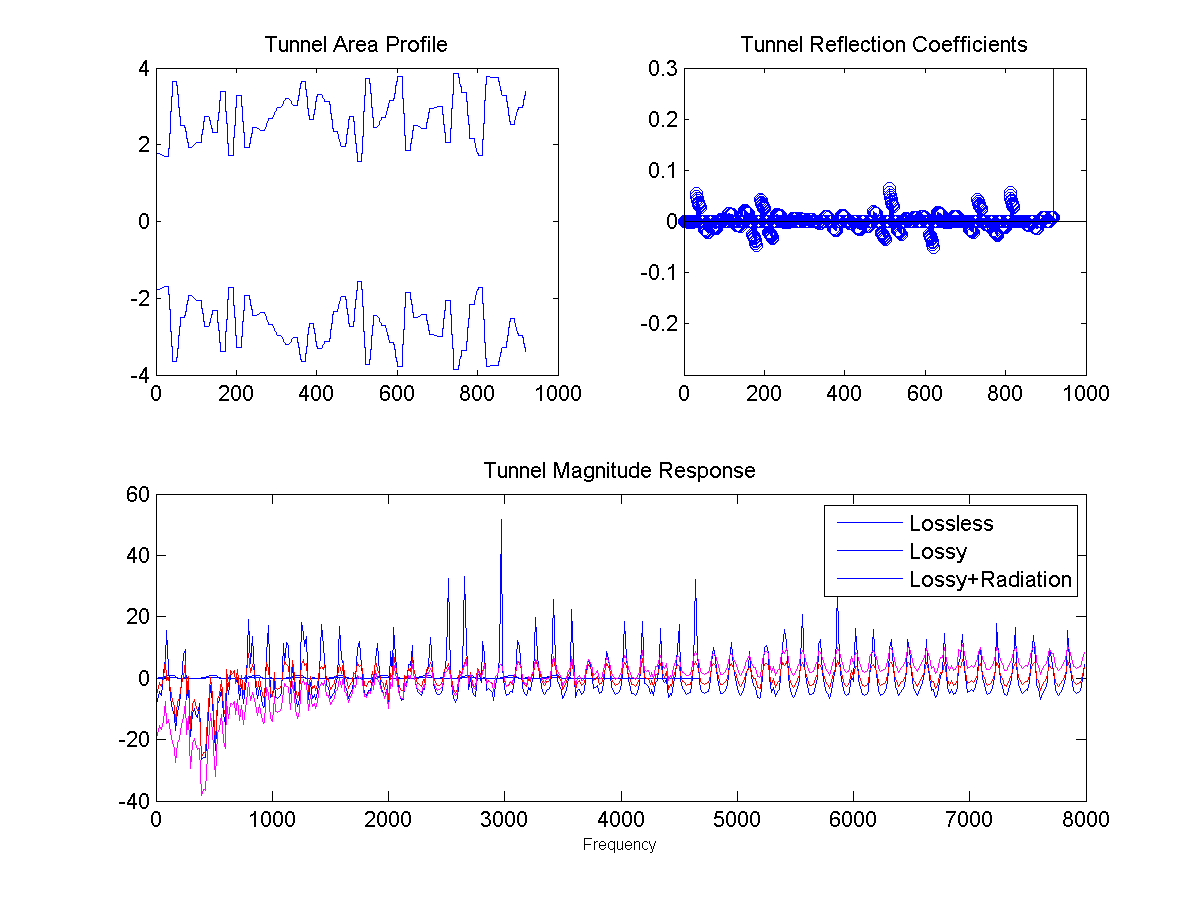
tunnel-spokenphrase.wav
(original)
tunnel-stravinsky.wav
(original)
En.Ibrahim
/ April 1, 2014 QuoteNice work for voiced speech , but what about the other part of speech (unvoiced)?
Berk
/ July 19, 2014 QuoteGreat job ! I have a project about Speech Gender Conversion. You can have a look if you are interested. Source code and project report are included.
http://berksoysal.blogspot.com/2014/07/speech-processing-project-speech-gender.html
Tom Tonon
/ March 13, 2015 QuoteHi Matt,
Very interesting results for the sound of spoken vowels. Can you please tell me if there is an analytical solution for the resonant frequency of two simple tubes of different cross sections and lengths, when butted together, with one end closed. This is the so-called Two Tube model? If so, can you present it here? Thanks much!
Tom